MySQL系列二之基础使用
这个是MySQL系列的第二部分还是主要以基础使用为主,本篇主要介绍排序和多表操作相关的基础知识。所有讲解都是基于MySQL 8.0以上版本。
摘要和排序
order by
mysql 排序的关键字为order by,默认排序是升序(ASC),降序的关键字是DESC,有一点需要留意的是,如果有SQL语句中有where子句,则order by 必须放在where 语句后面。多个条件排序则用逗号隔开。
-- 默认学生表,字段有id,class_id,name,birthday,sex
-- 根据姓名进行降序排列
select * from stu order by name desc;
-- 必须放在where语句后面
select * from stu where id >=2 order by name;
-- 多条件排序
select * from stu order by sex asc,birthday desc;上面为通用的排序方式,MySQL同时也支持自定义排序通过**filed()**函数,field(value,str1,str2),value与str1、str2比较,返回1、2,如遇到null或者不在列表中的数据则返回0,当然后面也可以增加更多的str3,str4。
-- 根据姓自定义排序
SELECT * FROM stu ORDER BY FIELD(left(sname,1),'何','赵');count函数
count(字段) 函数不会统计null值,使用count(*)时会将null统计进去。
-- 统计class_id 字段不为null 的条数
SELECT COUNT(class_id) FROM stu;
-- 和上面语句等价
select count(*) from stu where class_id is not null;min/max 函数
计算最小值或最大值
-- 获取最小的学生出生年份
SELECT year(max(birthday)) from stu;SUM/AVG函数
统计和,统计平局值
-- 统计学生的平均年龄
SELECT ROUND(AVG(TIMESTAMPDIFF(YEAR,birthday,now()))) FROM stu ;distinct 函数
distinct用于去除结果集中的重复记录
-- 获取所有班级编号
SELECT DISTINCT class_id AS class FROM stu WHERE class_id IS NOT NULL;group by
在说group by 之前,我们先了解一下MySQL 的查询模式,mysql可以运行在不同sql mode模式下面,sql mode模式定义了mysql应该支持的sql语法,数据校验等!
-- 查看全局的sql_mode
SELECT @@GLOBAL.sql_mode;
-- 设置全局的sql_mode
SET GLOBAL sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';不同的sql_mode
| sql_mode | 说明 |
|---|---|
| ONLY_FULL_GROUP_BY | 对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中 |
| STRICT_TRANS_TABLES | 在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制 |
| NO_ZERO_IN_DATE | 在严格模式下,不允许日期和月份为零 |
| NO_ZERO_DATE | 设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。 |
| ERROR_FOR_DIVISION_BY_ZERO | 在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常 |
| NO_AUTO_VALUE_ON_ZERO | 该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户 希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。 |
-- 去除本次链接的sql_mode,ONLY_FULL_GROUP_BY
SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
-- 根据班级分组查询最小出生日期姓名
SELECT min(birthday),sname FROM stu GROUP BY class_id;使用GROUP BY将数据分组后,还可以使用HAVING过滤分组,规定包括哪些分组,排除哪些分组
SELECT class_id FROM stu GROUP BY class_id HAVING count(*)>2;多表操作
在实际操作中很多时候是一张表不能解决,我们需要从多张表中获取数据,或者通过其他表的数据删除另外一张表的数据,这个时候就需要多表操作了。表的关系可以分为一对一,一对多,多对多。
先看下图,一下所有的inner可以通过该图来理解。
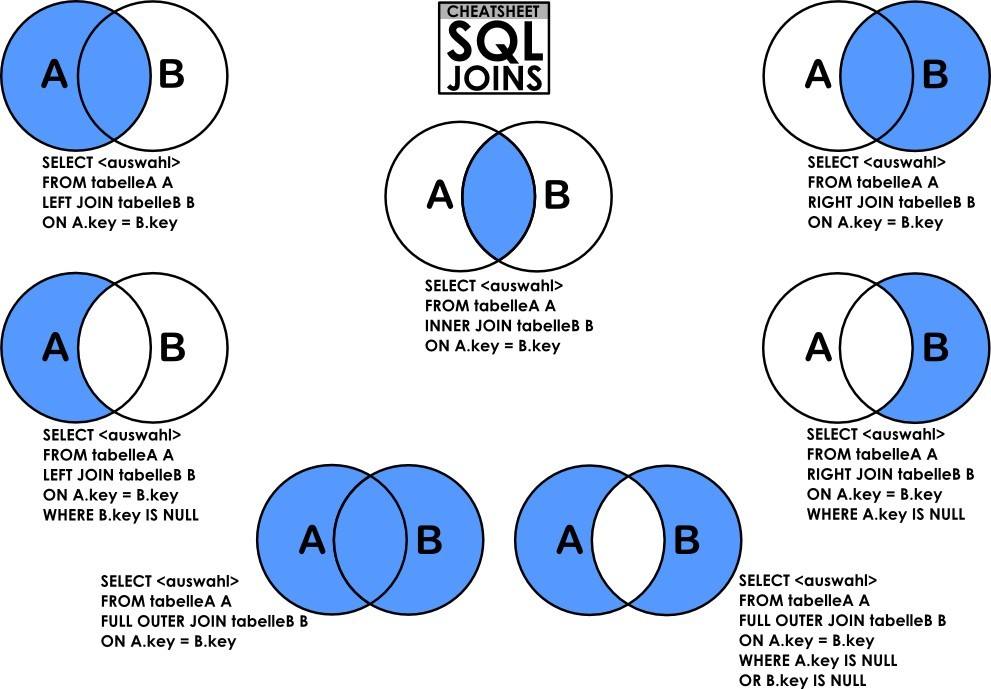
INNER
所有多表操作都可以简单理解为,把多个表联系成一个表,最终思想成面上当成一个表对待。使用inner join 后面跟着ON,ON后面跟的是条件
-- 获取用户信息
select * from stu as s,user_info as i where s.id = i.stu_id;
-- 使用inner 来进行多表查询,和上面的语句是等价的
SELECT * FROM stu AS s INNER JOIN user_info as i ON s.id = i.stu_id;OUTER JOIN
外链接包括LEFT JOIN 与 RIGHT JOIN ,可以简单理解为 LEFT JOIN会包含左侧所有表记录,RIGHT JOIN 会包含右侧表全部记录。
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据。依旧从笛卡尔积的角度讲,就是先从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录。
-- 获取没有设置QQ的用户
SELECT s.sname FROM stu AS s LEFT JOIN user_info as i
ON s.id = i.stu_id
WHERE i.qq is null;同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。再次从笛卡尔积的角度描述,右连接就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上右表中剩余的记录。和left join 是相反的。
-- 哪个班级没有学生
SELECT sname,c.id,c.cname FROM stu AS s RIGHT JOIN class as c
ON s.class_id = c.id
WHERE s.id IS NULL;SELF JOIN
SELF JOIN为自连接即表与自身进行关联。虽然自连接的两张表都是同一张表,但也把它按两张表对待,这样理解就会容易些。子查询操作和自连接操作都能达到相同的查询结果,但是子查询操作的是两次性能会比自连接消耗性能。
-- 使用子查询操作
SELECT * FROM stu WHERE class_id =
(SELECT class_id FROM stu WHERE sname = '后盾人')
AND stu.sname !='后盾人';
-- 使用自连接操作
SELECT s1.sname,s2.sname FROM stu as s1
INNER JOIN stu as s2
ON s1.class_id = s2.class_id
WHERE s1.sname = '后盾人' AND s2.sname !='后盾人';UNION
UNION 用于连接多个查询结果,要保证每个查询返回的列数与顺序要一样。
- UNION会过滤重复的结果
- UNION ALL 不过滤重复结果
- 列表字段由是第一个查询的字段
-- 查询年龄最大与最小的同学
(SELECT sname,birthday FROM stu ORDER BY birthday DESC LIMIT 1)
UNION
(SELECT sname,birthday from stu ORDER BY birthday ASC LIMIT 1)
ORDER BY birthday DESC;本文参考链接[后盾人MySQL教程]([http://houdunren.gitee.io/note/mysql/2%20%E5%9F%BA%E6%9C%AC%E6%93%8D%E4%BD%9C.html](http://houdunren.gitee.io/note/mysql/2 基本操作.html))
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!